Database High Availability Best
Practices
James Viscusi, Oracle Corporation
Pradeep Bhanot, Oracle Corporation
Executive Overview
A much-discussed aspect of ‘The internet changing everything’ has been the increasing focus on availability in open systems applications. Seemingly overnight, application developers and support staffs were faced with the latest buzzword ‘24x7’ and were given sometimes ill-defined requirements to have systems and applications available at all hours. IT management, developers, support staff, DBAs, system and network administrators were then faced with the problem of translating those requirements into an achievable reality, integrating solutions from multiple hardware and software vendors.
Oracle’s philosophy with our latest generation of products is to provide a set of components that will present to the users of a system a seamless picture of application availability, even though any one component may be experiencing a failure. Through out the remainder of this paper, we will review the justifications for developing a highly available solution, justifying the expense and trouble, explore some of the key components available in the Oracle product set and illustrate their use with a sample system architecture
Oracle has been serious about providing high application availability to customers since it first introduced support for a clustered database in Oracle version 6.2 on VMS in 1990. Even back then Oracle consulting would write scripts to provide a simple standby database running recovery at a backup site. Today Oracle is setting the pace in open systems High Availability with its new tagline: Unbreakable.
Uptime
– What Does an Application Really Need?
While Oracle continues to make the implementation of highly available systems easier, there are still associated architecture, planning, development and maintenance costs. The first step in the development of any system deemed to be highly available is to determine the true requirements.
Many developers say they have a 24x7 database without a clear understanding of what that means to their application and a clear understanding of the actual business processing requirements. When assessing your application to determine if it requires the precautions necessary to make it highly available consider questions like, ‘Is there a short window of time at any point (daily, weekly, monthly) when the database can be unavailable?’ If so, it may be possible to use some of the less expensive/more time-consuming alternatives for availability.
Myths
of uptime numbers
The following table provides a guideline when defining high availability requirements. Downtime for hardware and software upgrades also counts when considering availability requirements. Implementing and maintaining a highly available system can require a large investment in hardware, software and a further investment of staff time to construct the recovery procedures, test the solution and monitor the system to reduce the overall recovery time. Business users, management and IT staff should all understand at design time the investment required in setting up and maintaining a 24x7 system.
|
Availability Needed |
Downtime (min/year) |
Downtime (hour/year) |
|
99.00% |
5,256 |
87.6 |
|
99.25% |
3,942 |
65.7 |
|
99.50% |
2,628 |
43.8 |
|
99.75% |
1,314 |
21.9 |
|
99.90% |
526 |
8.76 |
|
99.99% |
53 |
0.88 |
|
99.999% |
5 |
0.08 |
System designers often discuss availability in terms of 100% uptime. Our goal is to make the user’s perception that the system is available all the time or 24x7 even though an individual component may have failed. We want to do this while keeping the cost of implementing such a system affordable and the management of the overall solution straight forward and easy.
A business needs to balance the cost of providing a given level of availability vs. cost of downtime. According to a survey by Contingency Research Planning, Livingston, N.J., the leading causes of computer downtime for more than 12 hours were 31% Power Related (Surge etc.), 20% for storm Damage, 16% for Burst Pipes, 9% for Fire and Bombing, 7% Earthquakes and 4% attributed to Other causes. A study conducted by the University of Texas uncovered that all companies who suffer from major data loss and extended downtime: 6% survive, 43% never reopen and 51% close within 2 years (source CIO Magazine April 1998). It is interesting to note that, although 98 percent of CIOs polled believe it is important to have a disaster recovery plan, 25 percent do not have one in place. This is according to a poll conducted by RHI Consulting and published at (http://www.cio.com/archive/040198_disaster.html).
What
could happen, what could happen to you?
The next part of understanding the issues
required to design a highly available application is to understand the
potential problems and pitfalls. One
part of this can be understood by understanding common causes of downtime in
the industry. As a sample, the results
of a recent survey on reasons for data loss as published in the Disaster
Recovery Journal are summarized in the chart below.
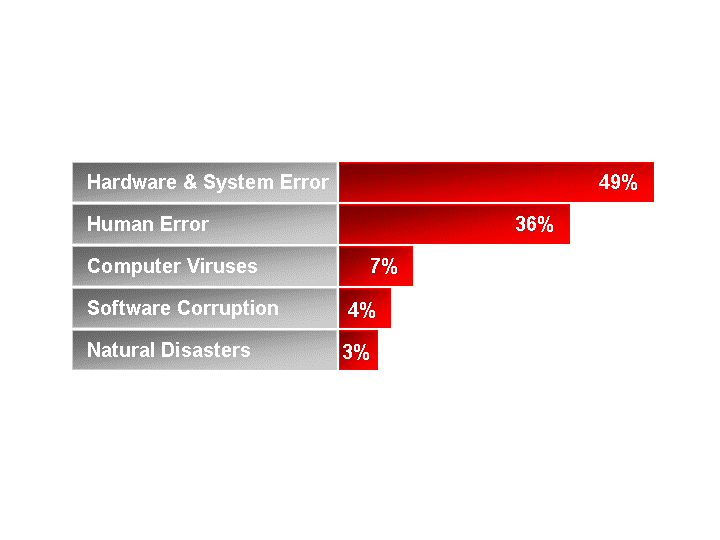
2001 Survey of 184 sites
From this data, we can identify the two most likely causes of an outage are Hardware /Software errors and human errors. When discussing equipment errors, this data allows us to understand and justify the cost of appropriate, fault tolerant hardware and software solutions. It’s interesting to not that the second largest cause of outage and data loss is human error. This only reinforces the point that appropriate and detailed procedures must be in place and review (and practiced) regularly to insure the highest levels of uptime. In addition to the categories of errors described here, it would be prudent to review the particular application environment for additional potential sources of outage and develop appropriate plans.
Test
it!
While discussing human error, it is worthwhile to mention an often over looked best practice for a true HA environment. This is the creation and maintenance of an adequate test environment that is capable of producing load representative of the production environment. As was discussed earlier, human error was the second largest cause of data loss in a survey of companies that experienced an outage. Along with automation, scripting and clear procedures, testing is key to reducing the chance that human failure will cause or extend an outage. Oracle considers maintaining an appropriate test environment a key best practice to assure continued High availability for any system.
An example of a site where testing really paid off is Merrill Lynch. On September 11th, Merrill Lynch one of the world's leading financial management and advisory companies, who test critical applications for disaster readiness quarterly, where challenged with an previously unthinkable disaster, when terrorists struck the Twin Towers in New York. A core data processing center within two blocks of ground zero made a decision to redirect operations to a backup data center in the City of London, England. Within 11 minutes of making the decision, London was able to take over operations by activating their Oracle standby databases with no loss of data.
Capturing
the definitions – the Service Level Agreement (SLA)
Once the systems’ requirements
are defined, the need to be documented and maintained in a fashion that is
understood by all parties. An industry
standard practice is to create a Service Level Agreement (SLA) that would
clearly define the periods of uptime, allowed downtime for maintenance windows,
and recovery time for each type of anticipated outage.
In addition to defining the
uptime requirements, the procedure for recovering based on the outage and
command structure should also be defined.
Issues such as who should be notified, and how they should be contacted
should be clearly spelled out. Also,
the issue of who should declare an outage and start the failover process should
be defined. For a system with very high
availability requirements, much of the outage window could be lost if there is
not a clear decision to start the failover process or if that process is not
completely automated.
Also these procedures should define the exact steps for activating the failover plan. As many of those steps as possible should be scripted and tested in advance. These scripts and plans should be tested in advance of their activation in a real failure and should for the basis of an ongoing test methodology.
The
Goals of The Oracle Solution
As a part of our continuing
improvements to the Oracle product set in the areas of Manageability and
availability Oracle has made improvements to our products with the following
goals in mind:
Once you have a common definition of uptime, and a common understanding of what any given system’s uptime should be, plus an understanding of the errors that you may encounter, choose from the array of solutions that Oracle provides. The next section of this document will review some of the new or key High Availability features with these features in mind.
Base features
The Oracle9i release of Data Guard has built upon some features in the core database server product that contribute directly to the potential availability of any system.
Features
that improve uptime
Features that address Human Errors
Given Human Error is so commonly involved in data loss, Oracle9i has many features to address this exposure to a customers data.
Recovery Manager (RMAN)
Oracle’s Recovery Manager is Oracle’s strategic tool to manage backup and recovery operations. Recovery Manager provides a tightly integrated method for creating and managing backups, restoring and recovering the Oracle database.
There are a number of significant benefits to using Recovery Manager. These are possible because the Oracle database server is managing the backup and restore operations.
RMAN greatly simplifies recovery, by automatically identifying the appropriate backups and archive logs that are required to recover the database.
Block
Media Recovery (BMR)
The block media recovery feature is a technique for restoring and recovering an individual corrupted data block or set of corrupted data blocks within a datafile. When a small subset of blocks in the database require media recovery, it is more efficient to selectively restore and recover just those blocks. Only blocks being recovered need to be unavailable, allowing continuous availability of the rest of the database during recovery. Block media recovery provides two main benefits over file-level recovery: lowering the Mean Time To Recover (MTTR) and allowing increased availability of data during media recovery.
BMR will reduce the MTTR in situations where
only a small subset of blocks in a database file in need of media
recovery. Without block-level recovery,
if even a single block is corrupt the administrator must restore a backup of
the entire file and apply all redo changes generated for that file since that
backup.
Hardware Assisted Resilient Data (HARD) initiative
Oracle's Hardware Assisted Resilient Data Initiative is a comprehensive program designed to prevent data corruptions before they happen. Data corruption, while rare, can have a catastrophic effect on a database, and therefore a business. By implementing Oracle's data validation algorithms inside storage devices, Oracle will prevent corrupted data from being written to permanent storage. This type of end-to-end, high level software to low level hardware validation has never been implemented before. HARD will eliminate a large class of failures that the database industry has so far been powerless to prevent. RAID (Redundant Array of Independent Disks) has gained a wide following in the storage industry by ensuring the physical protection of data, HARD takes data protection to the next level by going beyond protecting physical bits to protecting business data.
The classes of data corruption that Oracle plans to address with HARD include:
The HARD initiative includes several technologies that can be embedded in storage devices to prevent all these classes of corruption. Oracle’s storage partners will roll out these technologies over time.
Storage Configuration
Configuring the storage subsystem optimally
for the database is a very important task for most system and database
administrators. A poorly configured
storage subsystem can result in I/O bottlenecks and reduced protection from
device failures. The SAME configuration
model offers a a scheme that addresses the availability and performance
challenges administrators face. SAME,
an acronym for Stripe and Mirror Everything has
been developed by Oracle experts who have done significant work in researching
optimal storage configuration for Oracle database systems. This model is based on four simple proposals
(i) stripe all files across all disks using a 1 megabyte stripe width, (ii)
mirror data for high availability, (iii) place frequently accessed data on the
outside half of the disk drives, (iv) subset data by partition and not by
disk.
Stripe
all files across all disks using a 1 megabyte stripe width
Striping all files across all disks ensures
that full bandwidth of all the disks is available for any operation. This equalizes load across disk drives and
eliminates hot-spots. Parallel
execution and other I/O intensive operations do not get unnecessarily
bottlenecked because of disk configuration.
Since storage cannot be reconfigured without a great deal of effort,
striping across all disks is the safest, most optimal option. Another benefit of striping across all disks
is that it is very easy to manage.
Administrators no longer need to move files around to reduce long disk
queues, which frequently has been a non-trivial drain on administrative
resources. The easiest way to do such
striping is to use volume level striping using volume managers. Volume managers can stripe across hundreds
of disks with negligible I/O overhead and are, therefore, the best available
option at the present time. The
recommendation of using a stripe size of one megabyte is based on transfer
rates and throughputs of modern disks.
If the stripe size is very small, the disk head has to move a lot more
to access data. This means that more
time is spent positioning the disk head on the data than in the actual transfer
of data. It has been observed that a
stripe size of one megabyte achieves reasonably good throughput and that larger
stripe sizes produce only modest improvements.
However, given the current trend in advances in disk technology the
stripe size will have to be gradually increased.
Mirror
data for high availability
Mirroring data at the storage subsystem level is the best way to avoid data loss. The only way to lose data in a mirrored environment is to lose multiple disks simultaneously. Given that current disk drives are highly reliable, simultaneous multiple disk failure is a very low probability event. In addition to disk mirroring, Oracle offers its own internal mirroring also. However, Oracle mirroring is limited to redo logs and control files only. It is a good practice to use Oracle mirroring on top of disk mirroring. This is because Oracle mirroring is more immune to logical data corruption. In the case of disk mirroring, logical data corruption in a redo log will be reflected on both the mirrors, while in the case of Oracle mirroring, data corruption in one redo log will likely not be duplicated on the mirror of that log. Therefore, both redo logs and control files should also be mirrored at the database level for high availability purposes.
Place
frequently accessed data on the outside half of the disk drives
The transfer rate of a disk drive varies for different portions of the disk. Outer sectors have a higher transfer rate than inner sectors. Also outer portions of a disk drive can store more data. For this reason, datafiles that are accessed more frequently should be placed on the outside half of the disk. Redo logs and archive logs can undergo significant I/O activity during updates and hence should also be placed on the outside portion of the disks. Since this can lead to an administrative overhead on the part of the database administrator, a simple solution is to leave the inside half of a disk drive empty. The is not as wasteful an option as might appear because due to the circular shape of the disks, typically more than 60% of capacity is on the outside half of the disk. Also the current trends of increasing disk drive capacities make it an even more viable proposition.
Subset
data by partition and not by disk
Sometimes it is necessary to separate or partition the overall data set. For instance, a database administrator may want to separate read only data from updated data on different volumes. In such cases, the partition should be created across all disks, and then concatenated and striped to form a separate volume. This separates the data files logically without compromising any of the advantages of the SAME methodology.
The primary benefit of the SAME model is
that it makes storage configuration very easy and suitable for all
workloads. It works equally well for
OLTP, data warehouse, and batch workloads.
It eliminates I/O hot spots and maximizes bandwidth. Finally, the SAME model is not tied to any
storage management solution in the market today and can be implemented with the
technology available today. For more
details on SAME methodology, please refer to Oracle technical paper “Optimal
Storage Configuration Made Easy” at
http://otn.oracle.com/deploy/performance/content.html.
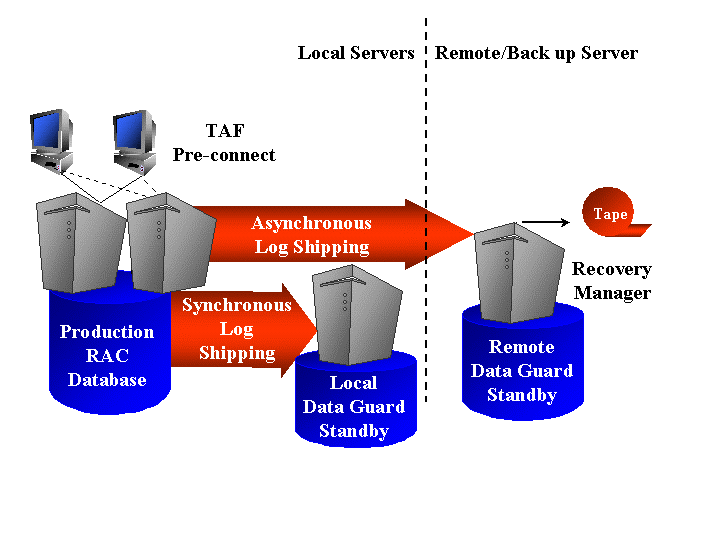
Oracle9i Data Guard
The goal of Data Guard is to maintain a real-time copy of a Production database to protect against corruptions, human errors, and disasters. In the event of a failure of the Production (or Primary) database, a Standby database can be activated to act as the new Primary database. Oracle9i Data Guard is the management, monitoring and automation software layer running above proven foundations of the Oracle9i Recovery and Standby database infrastructure components.
Orace9i Data Guard - Standby database was first delivered as part of the initial release of the Oracle9i Database in the summer of 2001. A Standby database maintains one or more, bit-for-bit replicas of the Primary database it protects. A SQL maintained Standby database is an integral part of a future release of Oracle9i, and is used to maintain a logical replica of a Primary database. A Data Guard configuration is comprised of a collection of loosely connected systems, consisting of a single Primary database and a number of Standby databases, which can be a mix of both traditional Standby’s and SQL Miantained Standby databases. The databases in a Data Guard configuration can be in the same data center (LAN attached) or geographically dispersed (over a WAN) and connected by Oracle Network Services.
When OLTP users add data or change information stored within an Oracle database, the database buffers changes in memory pending a request to make those changes permanent (when an application or interactive user transaction issues a COMMIT statement). Before the COMMIT operation is acknowledged by the database, that record is written to database redo log files in the form of a Redo Log record, which contains just enough information to redo the transaction in case of a database having to restart after system crash or during data recovery following data loss.
When using a standby database, as transactions make changes to the Primary database, the Standby database is sent redo log data generated by changes, in addition to being logged locally. These changes are applied to the standby databases, which runs in managed recovery mode in the case of a traditional standby database or applied using SQL regenerated from archived log files.
Whilst the Primary database is open and
active, a traditional Standby database is either performing recovery (by
applying logs) or open for reporting access. In the case of an SQL maintained
type of Standby database, changes from the Primary database can be applied
concurrently with end user access. The tables being maintained by SQL generated
from a Primary database log will, of course be read only to users of the SQL
Maintained Standby. These tables can have different indexes, and physical
characteristics from their Primary database peers, but have to maintain logical
consistency from an application access perspective, in order to fulfill their
role as a Standby data source.
Benefits Provided by
Oracle9i Data Guard
A standby database configuration can be deployed for any database. This is possible because, its use is transpartent to applications, as no application code changes are required to accommodate a standby. Customers can tune the configuration to balance data protection levels, application performance impact, network transport method and cost variables.
A standby database can be used to reduce downtime for planned outages such as operating system or hardware upgrades by performing a graceful role reversal or switchover operation between the primary and one of it’s standby databases.
Some of the key benefits of Data Guard in this architecture are:
These capabilities make a standby database a
popular high availability solution.
Real Application Clusters
Real Application Clusters harnesses the processing power of multiple, interconnected computers. Real Application Clusters software and a collection of hardware, known as a cluster, unite the processing power of each component to become a robust computing environment. In Real Application Clusters environments, all active instances can concurrently execute transactions against a shared database. Real Application Clusters coordinates each instance’s access to the shared data to provide consistency and integrity.
Oracle Real Applications Clusters supports additional Oracle features that enhance recovery time and minimize the disruption of service to end-users. These features provide fast and bounded recovery, enforce primary node /secondary node access if desired, automatically reconnect failed sessions, and capture diagnostics data after a failure. In addition, Oracle Real Applications Clusters can be integrated with the cluster framework of the platform to provide enhanced monitoring for a wide range of failures, including those external to the database.
Oracle Real Applications Clusters can recover more quickly from failures than traditional cold failover solutions. Because both instances are started an the database is concurrently mounted an opened by both instances, there is no need to fail over volume groups and file systems, because they are already available to all nodes as a requirement of Real Applications Clusters. There is also no need to start the Oracle instance, mount the database, and open all the data files.
If there are many connections that must be reestablished after failover, this task can be time consuming. Oracle Real Applications Clusters supports pre-connections to the secondary instance. In this case, the memory structures needed to support a connection are established in advance, speeding reconnections after a failure. Lastly, since both instances are running, the cache can be warm in both instances. In an active/active configuration, the cache on both nodes is warmed automatically.
Real Application Clusters Guard is built upon Real Applications Clusters running in a primary node/secondary node configuration. Much of the complexity in installation, configuration and management of the various components of traditional high availability solutions is avoided with the use of Real Application Clusters Guard. In this configuration, all connections to the database are through the primary node. The secondary node serves as a backup, ready to provide services should an outage at the primary occur. Also, Real Application Clusters Guard is tightly integrated with the cluster framework provided by the system's vendor to offering enhanced monitoring and failover for all types of outages.
The result of this integration of the cluster framework with Real Applications Clusters is the look and feel of traditional cluster failover. This is important as it means the solution works with all types of third-party applications that are designed to work with a single Oracle instance. However, the Real Applications Cluster Guard solution provides much faster detection and bounded failover in the event of a failure. It also provides improved performance after failover thanks to pre-connected secondary connections provided by Transparent Application Failover (TAF) and a pre-warmed cache on the secondary node.
Transparent Application Failover
Transparent Application Failover automatically restores some or all of the following elements associated with active database connections. It is this feature that truly allows an Oracle based system to present a user with the highest perceived level of availability. In any evaluation of availability, it is user perception that must be considered a key component. A user, presented with a clear message indicating a slight delay in processing, does not even need to know that a failover or recovery operation is occurring in the background. The follow features of TAF provide the DBA and developer with some tools for masking a failover from the user